Menu
Hybrid storage arrays that combine both flash storage and hard disks to provide high-performance storage at an affordable price to deliver the capacity and IOPS that a business needs to power their software applications, and that's where hybrid storage comes into play.
Whether you're a small start-up or an established enterprise, understanding how hybrid storage works can revolutionise the way you handle your data.
Hybrid storage is a cutting-edge approach to data storage that combines the best of both worlds: traditional hard disk drives (HDDs) and solid-state drives (SSDs). It's like having a powerful duo working in perfect harmony!
Now, you may be wondering, what makes this type of storage so special? Well, let me break it down for you. HDDs are known for their large capacity and affordable price point, making them ideal for storing vast amounts of data. On the other hand, SSDs are lightning-fast with impressive read/write speeds that can greatly enhance performance

In simple terms, it uses an intelligent software layer that automatically determines which data should reside on SSDs and which should be stored on HDDs. This dynamic arrangement ensures frequently accessed files are stored on SSDs for quick retrieval while less frequently used data resides on HDDs.
The beauty of the storage lies in its ability to optimise performance without breaking the bank. By leveraging the cost-effectiveness of HDDs and the speed advantages of SSDs, businesses can achieve faster access times while keeping costs under control.
Most hybrid storage arrays today consist of hard disks for capacity and SSD drives to deliver performance. Seagate manufacture a Hybrid SSHD drive that combines both of these elements and are primarily used in PC’s and games consoles. A hybrid system can be a JBOD combining both SSD and hard disks or a RAID system combining a RAID controller. The main issue when using flash storage as a cache or primary storage is that the RAID controllers are not designed to handle 10,000’s IOPS as they were originally developed to handle hard disks and many have firmware adapted to handle SSD. Many of the hybrid systems today are designed to scale for capacity by adding additional drive trays rather than increasing performance.
Additionally, hybrid offers improved performance by utilising a combination of local and remote resources. Frequently accessed data can be kept locally for fast retrieval while less frequently accessed data can be stored in the cloud for cost savings.
Hybrid arrays enables cost optimisation by allowing you to choose where to allocate resources based on usage patterns and budget constraints. You have greater control over how much storage is allocated on-premises versus in the cloud, resulting in potential cost savings.
Hybrid arrays bring together the best of both worlds - combining the advantages of local infrastructure with those offered by cloud-based services. It provides flexibility, scalability, disaster recovery capabilities, enhanced performance, and cost optimisation options that traditional storage methods may not offer.
Comparing these is like a Ferrari vs Mini both transport people and that’s where it ends. All-flash is the Ferrari and Mini the hybrid flash. All flash storage is designed to work directly using the system bus, processors and flash storage to deliver maximum IOPS. Whereas a hybrid flash array delivers whilst not as fast as all flash storage delivers higher IOPS than a comparable hard disk array. Hybrid arrays are primarily designed for mixed workloads and all flash array for dedicated tasks such as running an Oracle or SQL database.
By using Hybrid storage data is automatically migrated from the flash tier to the hard disk tier using software algorithms that track the data type and how often it is accessed. In addition, you can manually set certain applications to use just all flash or hard disk.

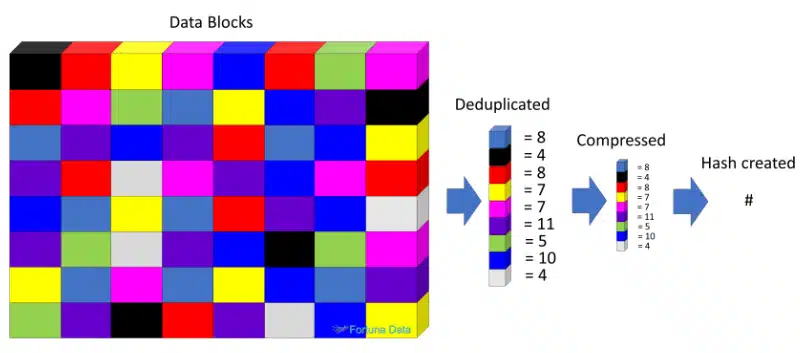
But many hybrid storage and all-flash arrays are using data deduplication to achieve far higher storage capacities in order to be more competitive in the storage arena. Deduplication is achieved by examining all of the blocks within a folder, disk volume or raid set and looks for block repetition, then removes duplicate blocks and then compresses the remaining blocks to create a hash # that references the location and quantity of the blocks for recall later. There are many different types of data deduplication source based, target based, inline, post, file, or block, fixed or variable length blocks but we are not discussing them here. Data deduplication requires powerful CPU’s and memory in order to rewrite the blocks and hash files. With increased processing power deduplication is becoming more prevalent in many mainstream storage systems and operating systems as costs come down.
Hybrid systems are a powerful solution that combines the best of both worlds - the performance of flash storage and the capacity of traditional disk-based storage. By intelligently tiering data based on its frequency of access, hybrid systems ensure that frequently accessed data resides in high-performance flash storage, while less frequently accessed data is stored on slower but more cost-effective disks.
In this article, we explored how hybrid storage works by leveraging intelligent algorithms to automatically move data between flash and disk tiers. This dynamic tiering allows businesses to optimise their storage infrastructure for both speed and cost-efficiency, resulting in improved application performance and reduced IT expenses.
The benefits of hybrid storage are numerous. With faster access speeds to frequently used data, businesses can experience significant improvements in application performance, leading to increased productivity and customer satisfaction. The ability to scale up or down as needed ensures flexibility without sacrificing performance or breaking budgets.
Furthermore, by combining flash and disk technologies into a single solution, hybrid arrays provide a seamless user experience without compromising on reliability or availability. Data redundancy measures are put in place to safeguard against hardware failures or disasters. In today's fast-paced digital world where businesses rely heavily on fast and efficient access to their data, adopting hybrid storage can be a game-changer. It offers the perfect balance between speed, capacity, scalability, and affordability.
If you want to know more please contact us using the details below.