Time and time again I hear the word Backup and the problems associated with it. Well this article will hopefully convince people and companies that if they archive more they can backup less!
Today some companies are selectively backing up data on a daily basis, in order to at least have 1 copy every 48 hours; this issue is not going to get easier and should be resolved.
Increasing Data Volumes
Data is typically growing faster than current backup systems can cope. It is predicted by 2024 global digital data volumes will exceed 140 Zettabytes or 140 Trillion Gigabytes! That's an enormous amount of information stored somewhere in the world's data centres.
Backup Failures
I have lost count as to how many times people have mentioned “the backup failed again last night”. They can fail for so many reasons and it’s not all down to human error. With the ever increasing data sprawl, trying to keep a handle on this problem is always going to end in tears. In order to manage our backups we firstly need to manage our data more efficiently by prioritising the data into more manageable chunks.
Rather than create a single backup job to backup everything, try to prioritise and create clearly defined backup jobs. At least this way it should help to find out the individual causes of backup failure, rather than reading a huge report that lists everything, by doing this reports are easier to read and analyse. Ensure you then resolve the route cause and run the backup again.
Things to consider about backup:
Do you need to backup desktops or personal data?
Do you have the correct agents to backup your operating systems or platforms?
Should you be looking at an alternative supplier or vendor?
Have you removed or added additional servers or applications?
Do you have networking issues?
Do you have the correct access permissions to backup the servers?
Who has access to the backups and what level can they see?
When was the last time you performed a restore?
If you backup everything fantastic, but what if you need to restore everything if disaster strikes? Time is precious and backup is just a matter of housekeeping and continual management, by reducing data volumes will dramatically increase your chances of achieving a 100% success rate. In addition to this if the backup data is in the cloud, how quickly can you perform a restore?
Why do we backup?
In the event of a disaster we can restore to a point in time prior to the event.
Restore data in the event of malicious or accidental data erasure.
To protect against virus’s and hackers.
Restore data from one system to another.
In case something goes wrong with a system upgrade or patch.
What are the issues with backup?
Time constraints to backup everything.
Ever increasing data volumes.
Backup failure.
Financial impact of continuously renewing backup software and systems.
Managing backup software and agents.
To de-dupe or not to de-dupe? This is an interesting one.
Hard disk or tape?
Encrypt or not?
Onsite, offsite.
Media collection costs.
Data Management.
Regulation and compliance.
Data retention periods.
Wear and tear.
Financial Impact
Every so often a new faster technology comes along to hopefully alleviate some of the issues we are experiencing with backup. These technologies only provide a short term fix to a long term problem.
LTO-9 – Much greater tape capacity 18TB native/45TB compressed
VTL – A disk array with software that mimics a tape library
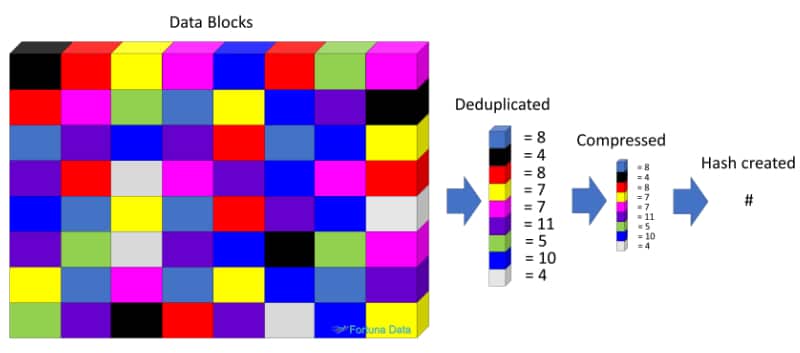
De-duplication – Looks for common blocks and creates a hash table
Compression – Gives us more for less, providing the data is compressible
RAID Array – Cheaper than a VTL and uses the backup software to create the virtual tape library
Change Backup Software - Do we upgrade or forklift upgrade to something else.
New infrastructure - More SAN storage and virtualised environment needs additional agents.
Systems outdated - Purchase new or upgrade existing technology
On-going cost of software and hardware maintenance renewals
On-going purchase of additional backup agents and software
Purchase additional backup tapes or storage
Increasing offsite storage costs
The indirect costs associated with backup are as follows:
Purchase / upgrade tier 1 storage to cope with increased data volumes
Slower performance due to increased disk fragmentation
Increased costs for support, maintenance and upgrades
Greater deployment of servers and management
Increased running costs including energy
Increased staffing costs
To De-dupe or not De-dupe that is the question
More hype has been placed on this backup saviour called Data De-duplication than any other backup technology. Why has this technology so over hyped and mis-understood? Firstly let’s explain how data de-duplication works.
Data De-duplication is a technology that initially creates a full backup of your data, but not as files only as hash tables. These data de-duplication solutions can be pre, post or in-band let me explain.
Pre – The data is analysed and hashed before landing on the disk. Usually requires a large amount of cache and fast processors.
Post – A backup is taken and the file is stored on disk, once the backup is finished the hashing takes place. Requires more disk than the Pre process, but typically faster.
In-band – As the files are backed up they are on the fly hashed and then placed on disk. Requires fast processors and not as fast as the previous two.
In addition to the above they can also be:
File level data de-duplication typically provides compression rates up to 5:1 and removes repetitive files.
Fixed block data de-duplication provides compression rate up to 10:1. Views the blocks of a given fixed size and removes the repetitive blocks.
Variable block data de-duplication by far the best and most flexible technology providing compression ratios of 50:1 or more, although in real world applications you will get between 20:1 or 30:1 depending on data type.
Now whatever data de-duplication process we deploy, they all effectively do the same job. We now have a full backup and know it consists of repetitive blocks. The next time we perform the backup, we only need to backup the changed blocks and append the hash tables accordingly. The diagram below will hopefully explain how this works in more detail.
Data de-duplication is a great technology providing your data is not video, images or audio files as they do not really compress and can in fact expand to be larger than the original file.
File or Hash
Now remember earlier we mentioned that data de-duplication systems do not store files only hashes. This is a double edged sword great for reducing backup windows as we only backup the changed blocks, but restores take far longer.
Restore
We need urgently to restore downed systems, with a non de-duped solution just hit restore and the files come back instantly. Data De-duplication doesn’t work like this, here are the steps.
Providing your appliances are working and you can get access to them. Firstly re-constitute the de-duped blocks to files and then start the restore. This is fine providing you want to recover a small amount of data but typically it will take 2X longer to perform a restore using data de-duplication than a conventional backup. It also requires extra disk capacity to act as a staging area for the de-duped data to reside, prior to being fully restored.
Prolong the inevitable
Data De-duplication is not a backup utopia! It is a device that uses less storage space at the expense of restore times and complexity. It should not be viewed as a permanent answer to your backup; it will only delay the inevitable issue of backing up ever increasing amounts of data.
Data Encryption
Encrypting data will introduce a backup and restore overhead. There are many stories of data being lost or stolen, but there are also stories about organisations that did encrypt their data and can’t recover it.
This could be lost encryption keys, faulty systems etc. Police Forces do not like encryption as it adds a layer of complexity that causes more headaches than it solves. If you are sure you have procedures in place to protect your encryption systems, then this is a good idea. If however you change systems, software or lose the encryption keys what will you do with all your historical backup data?
WAN Bandwidth
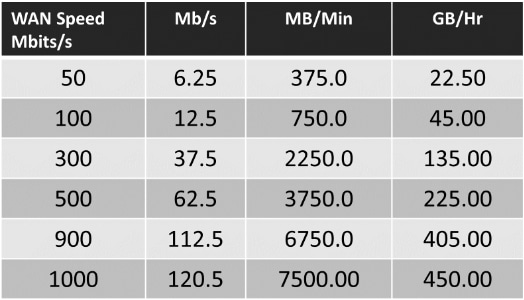
When synchronising data across wide area links it is an important consideration to find out the available bandwidth for synchronisation purposes. Below is a table of typical transfer speeds. Another thing to consider is when the synchronisation will be taking place, day/night/weekends, quality of the link and the actual available bandwidth that can is available, excluding other normal network traffic. All of this can have a dramatic effect on our ability to store data offsite.
Based on these WAN speeds to backup 2TB's of data offsite would take 4.4 hours over a 1000Mb line. Unless you have a dedicated leased line that guarantees your upload and download speeds, your real upload speed would probably be 1/8th of those indicated. So for example BT Full Fibre quotes 900Mbps download and upload 110Mbps. If we now have to upload the same 2TB of data it would take 44.44 hours!
Onsite / Offsite
Everyone should create a second copy of their data which should be stored in a “DATA SAFE” (not Fire Safe). This can be synchronising from Site A to B using hard disk or physically backing up two separate streams to two sites using tape. If you can’t afford the cost of a DR site make two copies and store one offsite.
Collection & Storage Costs
Whilst many organisations have 3rd parties collecting their media, the cost of this service rises with fuel costs, increased number of tapes etc. The only way to reduce these costs are to upgrade your tape technology to backup more data on less tapes or setup your own DR site and have the data sent across the LAN or WAN providing you have enough bandwidth. This is where data de-duplication comes in (see above).
Data Management
No matter what backup software a company runs, daily management reports are run to ensure the backups ran successfully. The more data, servers and applications we add, the more time we spend caring for our backups. Today companies employ staff to manage their backups full-time why? It’s all down to paranoia, we add more of everything and our worries grow that something somewhere is going to fail.
When I setup Fortuna Power Systems 29 years ago staff would spend 1-2 hours a day on backups, so what went wrong, surely today systems and technology are more reliable than they were 20 years ago? Yes, systems and software are more reliable and advanced, but the problem is we have far more data and servers performing tasks. Organisations that virtualise their infrastructures now have 10-20 servers running on their much bigger and more powerful server, so if someone pulls the plug on this we lose twenty servers and not just one! So the worry here is how to make the virtualised infrastructure highly available against such an event occurring.
Regulation & Compliance
Today more and more organisations are facing legislation to secure their data for regulatory, compliance or corporate governance. Trying to identify what should be kept or deleted becomes more difficult every day and for how long do we need to keep it? The problem is backup software isn’t designed to identify aged, changed or modified data. All it is designed to do is reset the archive bit, for the next backup. The challenge companies are going to face is where and how to store this legal information.
Data Retention
Data retention is defined by corporate or legal requirements. How long we have to archive and retain data is defined by these rules and policies.
How long do we need to keep our backups? Typically an organisation would create a backup schedule as follows:
Restore
A huge emphasis is placed on backup with little thought for the primary focus of backup and this is “RESTORE”. You have multiple backups stored across your estate. But none of it is any good if you changed your backup software 18 months ago! How many companies keep their backups and never bother to see if they can perform a restore on their legacy data, if they implement new hardware/software? The answer is not that many and who is going to admit to this oversight.
A restore of your information should be performed at least quarterly on a variety of different data types backed up from various servers and not the same server every time. At least this way should something serious occur you can be sure at least your restores will work as planned.
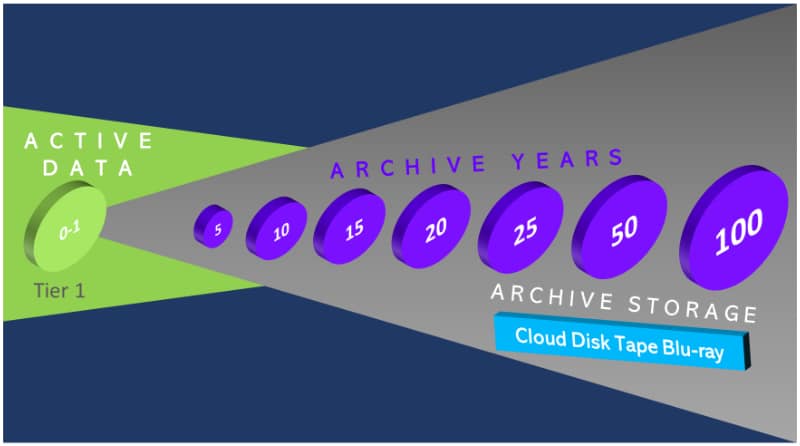
Data Archiving
Over the centuries the human race has tried to keep a history of events, discoveries and tragedies. Initially man carved etchings into stone or wood, then man discovered paper for almost 2000 years this was the way knowledge was passed on for future generations. Now in the 21st century a need to keep our digital history is becoming a huge headache for many organisations.
“The latest figures indicate that the world is creating on average 1.145 trillion MB per day. ”
In the world we live in today we are constantly generating information in the form of video, sound, e-mails, texts, music, databases, images, office documents, PDF's, and many other varieties of data are created daily. Some of this information is kept for a day whilst much of this information needs to be kept for a month a year or more than 50 years. We keep this information for a number of reasons; it could be legislation, regulation, insurance, assurance, research, intellectual property, personal, historical, medical or many others.
Storage Technologies
I have been involved in the data storage industry for over 40 years, during that time I have seen numerous technologies succeed and then fail because their development roadmap was to ambitious or someone designs, develops, invents something that appears better, cheaper, faster, easier to use and more reliable than what is currently available.
We are human and because of this we are seduced into purchasing these new revolutionary technologies. Unfortunately we do not always consider the long-term downsides of adopting these new products and it isn’t until we come to upgrade, maintain and enhance this product that we realise it is not as revolutionary as first thought and we are locked in to a solution that cannot evolve with our day to day business demands.
Archive Media
No matter what type of archiving technology you choose it is important to remember that the media is more important than the device. If you do need to keep media for a considerable time, always buy branded media from a known entity and ask for a certificate of conformance. These are sometimes difficult to obtain but should state that the media is certified for “x” years archive life. It might cost you a few pence more in the beginning, but it could save you thousands over the lifetime of the archive. To ensure a long-term archive you should ideally make three copies of the media and store it in three separate locations, if possible on three differing types of technology in the hope that in 50 years one of the technologies is still around to read the stored information.
Hard disk, tape, cloud or Blu-ray?
This depends on your corporate compliance and governance legislation.
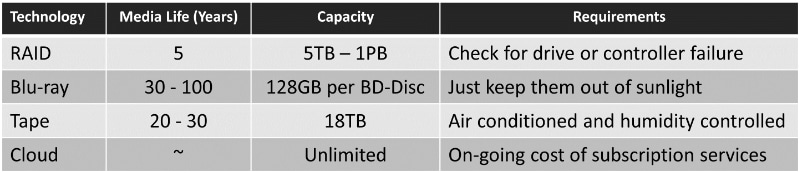
Tape
Advantages:
Tapes are portable for offsite storage
Tapes are low cost
Great for storing large amounts of data that needs to be restored quickly
When purchasing any media for backup or archive it is important to remember that the technology is only as good as the amount of money you have available to protect the data. So for example a backup tape might have a manufacturer’s life of 30 year these claims are made because the tape has been tested in perfect conditions and accelerated tests to achieve the results.
The cost of storing information increases yearly, this could be storage space, media costs, energy consumption, replacement costs etc. Clearly the archive media we choose needs to provide greatest long term costs savings for preserving the information and this is the challenge.
Why archive?
As mentioned throughout this site the issues of backup are becoming increasingly problematic. A failure to address the fundamental problem that data volumes are overwhelming the primary storage systems will inevitably result in data loss.
"80% of stored data is inactive after 60 days"
Numerous organisations have a huge on-going investment in purchasing data storage systems and this investment is increasing year on year as the demands to store more information increases. After 3-5 years this equipment is then replaced.
With the implementation of a Data Archive solution we can actually extend the life of this investment by moving the data to a secure active archive, thereby freeing up valuable disk space on high performing storage solutions and slowing down the necessary and ongoing investment of more storage space giving a huge ROI benefit. An additional benefit with a tiered data archive is that you might be able to utilise your existing older storage systems to archive data.
As a consequence the size of online data volumes are spiralling out of control and storage management has become an ever-increasing challenge.
Buying bigger and faster storage systems is not solving the problem of data identification. How we classify our data is going to become more of an issue than people first thought. Now we know tools exist to move data by date, last modified, file size, extension, user, file type etc, but how many companies are using this technology?
Archive Storage
Once we have an archive, whether this is static, near line or offline you need to consider whether the archive will remain on the same site as the primary data or relocate the archive to another office or even replicate the archive regularly to the DR site. In the event of a disaster your primary concern should be to restore your most recent information first and then restore the archive if required.
Data Cost
All information that we generate has a cost, companies often mention that the latest data residing on tier 1 storage has the most value. I do not agree with this statement for simple reason that important architectural/engineering drawings, films, health or legal documents etc are important long after they were initially created and if anything are more valuable than when first stored.
Data Archiving will achieve the following:
Current storage technologies
Below is a list of differing storage technologies which we could utilise to provide an archive. Storage technologies and archive life of media.
Access speeds and energy consumption
Reliance on other technologies to read the data
Technology Refresh
With any technology you should perform the following:
Archive More
There is no Silver Bullet to the issue of Backup or Archiving. By careful planning a happy medium should be achieved to ensure your most recent data is backed up daily and archived information retained for “X” days, months, years.
An archive needn’t be permanent; it could be a SATA disk array that only needs to be backed up once a month. Just deploying this affordable storage would free up your tier 1 disk space, removing none corporate data from the network would free up disk space, reduce network traffic and reduce your backup window. These simple strategies can be easily achieved with a little time, thought and money. We are able to provide a solution that, really will Backup Less and Archive More.
Call us on +44 (0)1256 331614or email: solutions@data-storage.uk and we will assist in any way we can.