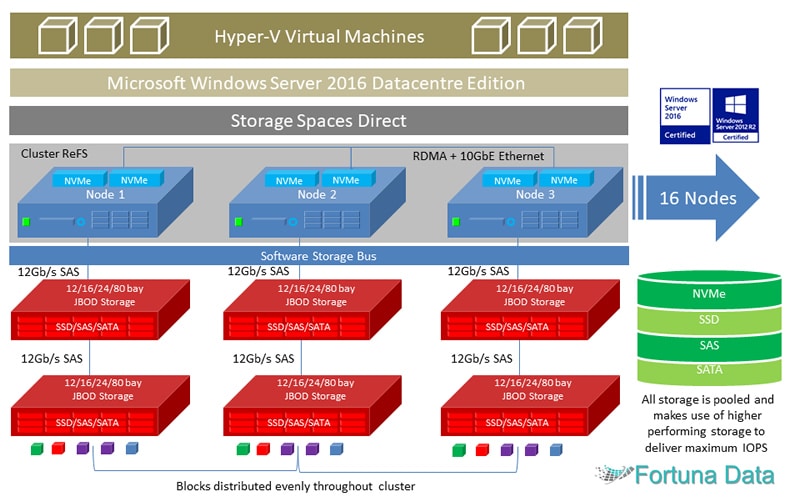
Microsoft Storage Spaces Direct virtualizes all storage devices attached to a server to create a highly available/scalable clustered software defined storage solution. Each server runs Windows Server 2016 Data centre or Windows Server 2019 Data centre and SSD manages all of storage attached to that server including NVMe, SSD, SAS, SATA drives to create a high performance clustered pool of storage that can be used to provide Hyper-V VM’s flexible storage at a fraction of the cost of traditional SAN or NAS arrays.
In essence Microsoft Storage Spaces Direct is a hyper-converged infrastructure with the ability to provide up to 13.7 million IOPS! The Microsoft Storage Spaces Direct architecture allows you to deploy a cluster in under 15 minutes. The architecture is completely self healing with the ability to add more nodes as and when required, with support for 16 servers and over 400 drives, for up to 1PB of storage per cluster!
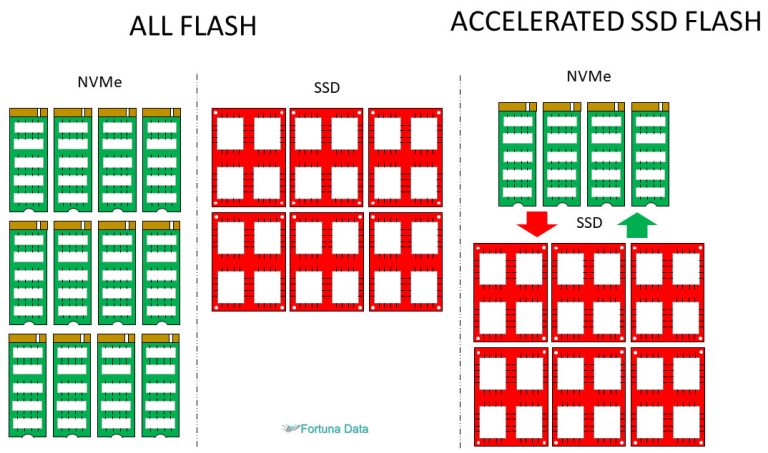
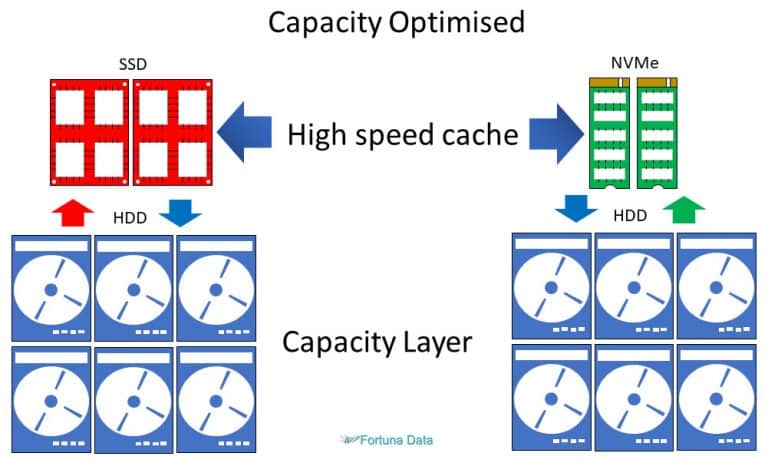
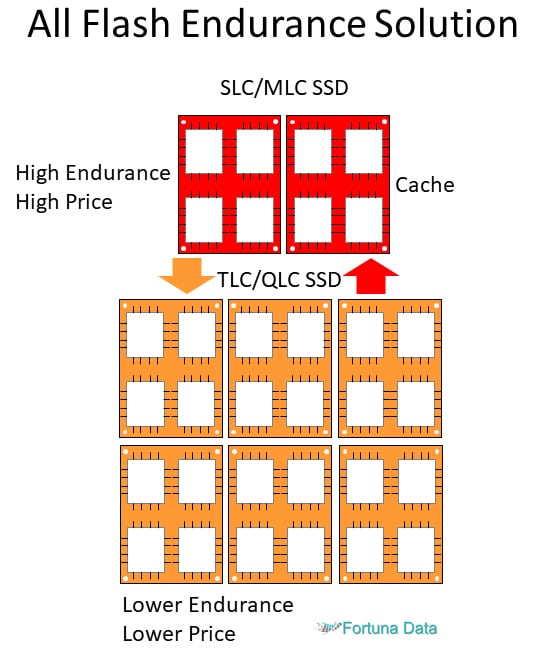
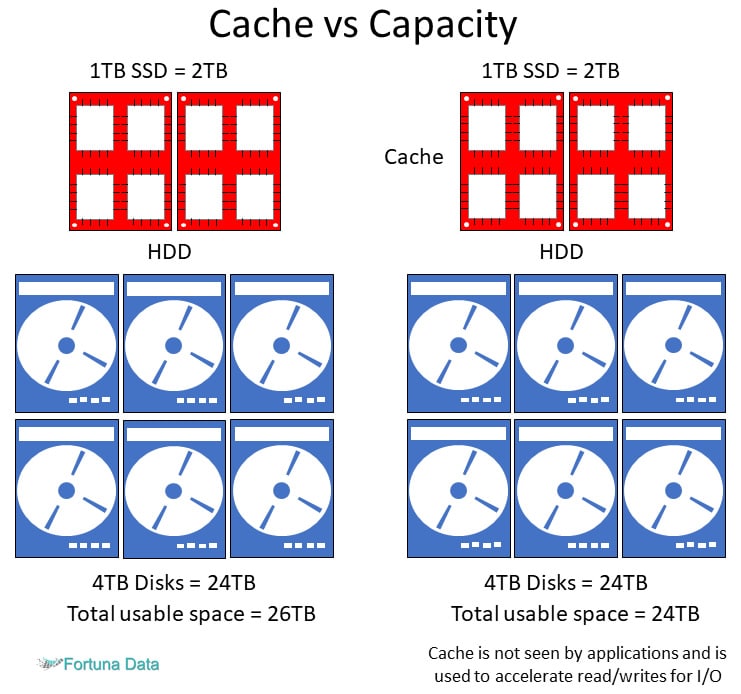
Microsoft Storage Spaces Direct features a built-in server-side cache to maximise storage performance. It is a large, persistent, real-time read and write cache. The cache is configured automatically when SSD is enabled. In most cases, no manual management whatsoever is required. How the cache works depends on the types of drives present.
ReFS
Resilient File System (ReFS) is Microsoft’s newest file system, designed to take advantage of new drive technologies, scale efficiently to large data sets across diverse workloads, provide data protection and self-healing against possible data corruption.
Resiliency
Integrity-streams - ReFS uses checksums for metadata and optionally for file data, giving ReFS the ability to reliably detect corruptions.
Storage Spaces integration - When used in conjunction with a mirror or parity space, ReFS can automatically repair detected corruptions using the alternate copy of the data provided by Storage Spaces. Repair processes are both localized to the area of corruption and performed online, requiring no volume downtime.
Salvaging data - If a volume becomes corrupted and an alternate copy of the corrupted data doesn’t exist, ReFS removes the corrupt data from the namespace. ReFS keeps the volume online while it handles most non-correctable corruptions, but there are rare cases that require ReFS to take the volume offline.
Proactive error correction - In addition to validating data before reads and writes, ReFS introduces a data integrity scanner, known as a scrubber. This scrubber periodically scans the volume, identifying latent corruptions and proactively triggering a repair of corrupt data.
Once these tiers are configured, ReFS use them to deliver fast storage for hot data and capacity-efficient storage for cold data:
All writes will occur in the performance tier, and large chunks of data that remain in the performance tier will be efficiently moved to the capacity tier in real-time.
If using a hybrid deployment (mixing flash and HDD drives), the cache in Storage Spaces Direct will help accelerate reads, reducing the effect of data fragmentation characteristic of virtualized workloads. Otherwise, if using an all-flash deployment, reads will also occur in the performance tier.
Performance
In addition to providing resiliency improvements, ReFS introduces new features for performance-sensitive and virtualized workloads. Real-time tier optimization, block cloning, and sparse VDL are good examples of the evolving capabilities of ReFS, which are designed to support dynamic and diverse workloads:
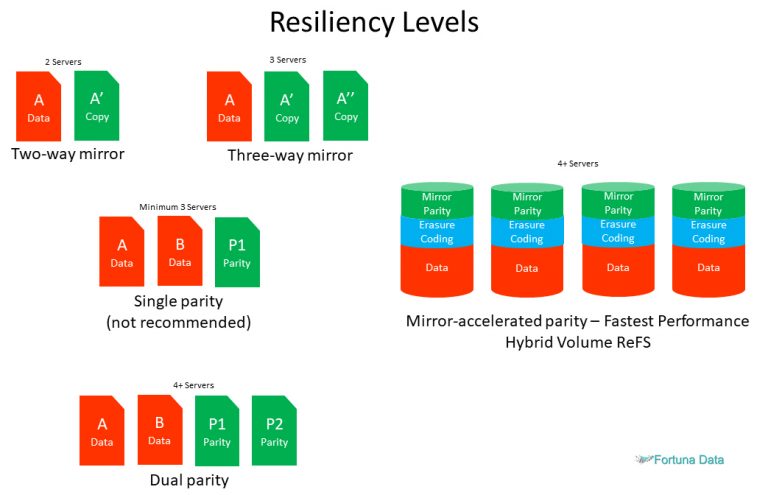
Mirror-accelerated parity delivers both high performance and capacity efficient storage for your data.
To deliver both high performance and capacity efficient storage, ReFS divides a volume into two logical storage groups, known as tiers. These tiers can have their own drive and resiliency types, allowing each tier to optimize for either performance or capacity. Some example configurations include:
SSD Storage Configurations
Accelerated VM operations - ReFS introduces new functionality specifically targeted to improve the performance of virtualized workloads: Block cloning – Block cloning accelerates copy operations, enabling quick, low-impact VM checkpoint merge operations.
Sparse VDL – Sparse VDL allows ReFS to zero files rapidly, reducing the time needed to create fixed VHDs from 10s of minutes to mere seconds.
Variable cluster sizes – ReFS supports both 4K and 64K cluster sizes. 4K is the recommended cluster size for most deployments, but 64K clusters are appropriate for large, sequential IO workloads.
Scalability
ReFS is designed to support extremely large data sets–millions of terabytes–without negatively impacting performance, achieving greater scale than prior file systems. SSD utilizes ReFS provides storage management across a maximum of 16 nodes and up to 400 drives. ReFS supports data deduplication with volumes up to 64TB and file sizes up to 1TB.
Supported drives:
NVMe
SSD
SAS
SATA
SMR (Shingled Magnetic Recording)
Storage Spaces with SAS JBOD drive enclosures
Deploying ReFS on Storage Spaces with shared SAS enclosures is suitable for hosting archival data and storing user documents:
Integrity-streams, online repair, and alternate data copies enable ReFS and Storage Spaces to jointly to detect and correct corruptions within both metadata and data.
Storage Spaces deployments can also utilize block-cloning and the scalability offered in ReFS.